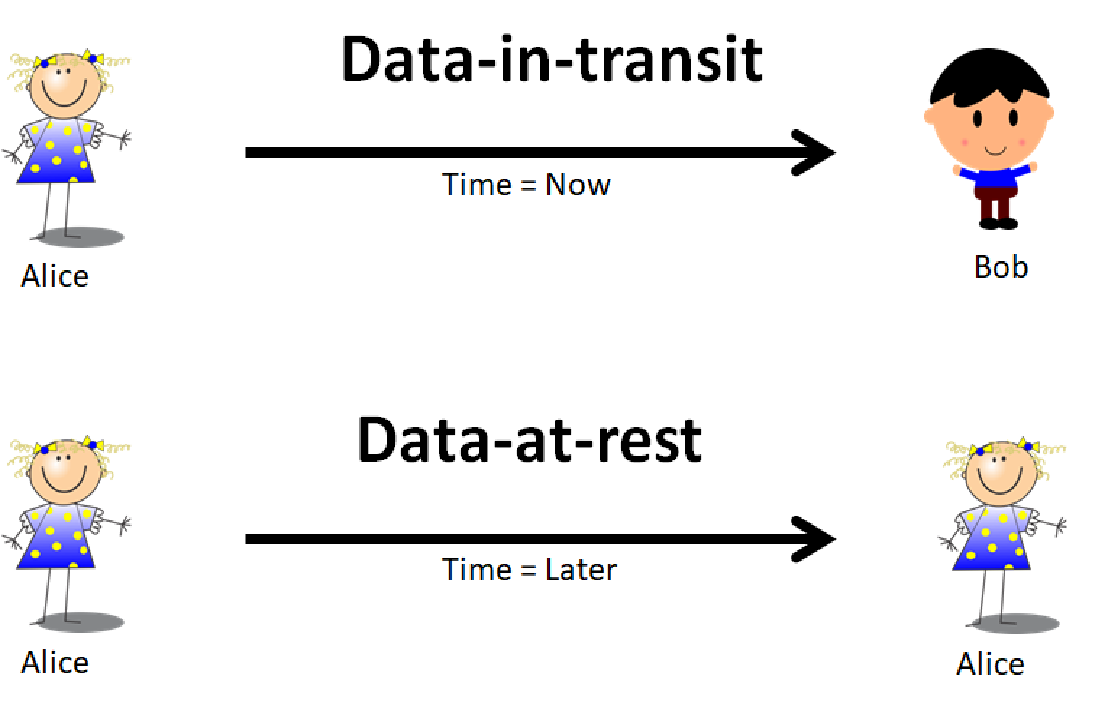
In computer systems, data that is stored onto static storage such as a flash drive or hard drive is referred to as “data-at-rest”. In contrast, data that is sent from point A to point B such as chat messages or network traffic is referred to as “data-in-transit”. The mindsets and toolsets that address these two states of data are very different especially when it comes to securing the data.
Data-at-rest techniques usually involve some form of encrypting the data prior to saving it onto the storage mechanism. This is usually called file encryption. Data-in-transit techniques usually rely on utilizing secure protocols which are methods of creating a secure pathway between the two endpoints thus anything sent between the two points are deemed secure. Nowadays, there are hybrids of these methodologies called End-To-End Encryption (E2EE) where messages may be encrypted prior to sending between the two points via a secure communication session. Today’s E2EE solutions offer some semblance of security but are often non-standard, hard to integrate, hard to manage and/or fall short of securing both states of data in a seamless, cohesive fashion.
In Data Centric Design (DCD), there is only one state of data: transmission. Data is generated, transmitted, and then consumed. The NUTS paradigm augments that DCD sequence to: data is generated, secured, transmitted, authenticated, and then consumed.
Storing data is an act of transmitting the data to the future.
For example, to perform data-in-transit securely usually requires two participants, Alice and Bob, to form a communications channel between them using a secure protocol and move data through the channel at time TNOW. When this is done properly, Alice can send Bob a message in near real-time securely. If we replace Bob with Alice and change the time to TLATER, this can become data-at-rest: Alice is securely sending a message to her future self.
Why does that matter? It simplifies what is traditionally considered two separate methods of securing data down to one unifying view. Thus, we are left to solve only the single problem of securing data for transmission. In this definition, the distinctions between data storage and transmission are blurred to mean the same thing, it’s just a matter of timing. In the TNOW case, the consumption of the data is done nearly instantaneously by Bob, but in the TLATER case, the consumption of the data is done at a later time by Alice. The example can be expanded to allow Bob or anyone else to consume the transmitted data at a later time.
| Time = TNOW | To Alice | To Bob |
| From Alice | Data-in-transit | Data-in-transit |
| From Bob | Data-in-transit | Data-in-transit |
| Time = TLATER | To Alice | To Bob |
| From Alice | Data-at-rest | Data-at-rest |
| From Bob | Data-at-rest | Data-at-rest |
A functional expression:
transmit(m, s, ts, r, tr)
where
m message
s sender
ts send time
r receiver
tr receive time
therefore
send_message(m, Alice, Bob) ≈ transmit(m, Alice, t0, Bob, t0)
save_to_disk(filename, m) ≈ transmit(m, Alice, t0, filename, t0)
read_from_file(filename) ≈ transmit(m, filename, t1, Alice, t1)
There are many ways to secure messages before transmission but very few offer a secure container that can be used for both states of data in a consistent, simplified and independent manner. What I’ve deduced over the years is that many problems that we have with our digital systems can be traced back to inadequately designed data containers. NUTS provides the technology to solve these inadequacies. In a later post, we’ll examine concepts called Strong and Weak Data Models.
This illustrates a core technique that Data Centric Design applies to problems big and small regardless of technical domains: root cause analysis. Finding the root cause of some problems may require you to re-frame the questions with a new perspective so if you solve the root cause then many of the symptoms never appear. The hard part is collecting a set of symptoms that appear unrelated and then looking for possible relationships.
Last week, DC CyberWeek presented very informative events, and many opportunities to network with some very smart people in the cybersecurity industry. The CyberScoop folks did an incredible job of organizing the whole affair. My deepest thanks to Julia Avery-Shapiro from CyberScoop for accepting our event idea, and for guiding us through hosting our first ever cyber security event. I cannot forget our attorney Jim Halpert for graciously offering the use of their offices at DLA Piper, and for the coordination wizardry of Susan Owens. I hope the folks who attended were rewarded with new information and ideas from our presentation.